Overview
LoopBack provides connectors for:
- Popular relational and NoSQL databases; see Database connectors.
- Backend systems beyond databases; see Non-database connectors.
Also see Community connectors for a list of connectors developed by the StrongLoop developer community.
Important:
This article is for developers who want to create a new connector type to connect to a data source not currently supported. It walks you through the MySQL connector implementation to teach you how to develop a connector for relational databases. However, many of the concepts also apply to creating a connector to other types of data sources.
Understand a connector’s responsibilities
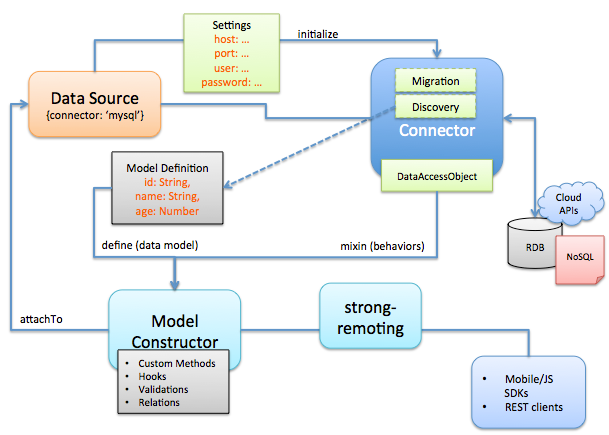
LoopBack abstracts the backend persistence layer as data sources that can be databases, or other backend services such as REST APIs, SOAP web services, storage services, and so on. Each data source is backed a connector that implements the interactions between Node.js and the underlying backend system. Connectors are responsible for mapping model methods to backend functions, such as database operations or calls to REST or SOAP APIs.
LoopBack models encapsulate business data and logic as JavaScript properties and methods. One of the powerful features of LoopBack is that connectors provide most common model behaviors “out of the box”, so application developers don’t have to implement them. For example, a model automatically receives the create, retrieve, update, and delete (CRUD) functions when attached to a data source for a database.
The following diagram illustrates how connectors fit into the LoopBack API framework.
 </figure>
</figure>
You don’t always have to develop a connector to enable your application to interact with other systems. You can use custom methods on a model to provide ad-hoc integration. The custom methods can be implemented using other Node modules, such as drivers or clients to your backend.
You may want to develop a connector to:
- Integrate with a backend such as databases.
- Provide reusable logic to interact with another system.
There are a few typical types of connectors based on what backends they connect to and interact with.
- Databases that support full create, retrieve, update, and delete operations
- Oracle, SQL Server, MySQL, Postgresql, MongoDB, In-memory DB
- Other forms of existing APIs
- REST APIs exposed by your backend
- SOAP/HTTP web services
- Services
- Push notification
- Storage
The connectors are mostly transparent to models. Their functions are mixed into model classes through data source attachments.
Most connectors need to implement the following logic:
- Lifecycle handlers
- initialize: receive configuration from the data source settings and initialize the connector instance
- connect: create connections to the backend system
- disconnect: close connections to the backend system
- ping (optional): check connectivity
- Model method delegations
- Delegating model method invocations to backend calls, for example create, retrieve, update, and delete
- Connector metadata (optional)
- Model definition for the configuration, such as host/URL/username/password
- What data access interfaces are implemented by the connector (the capability of the connector)
- Connector-specific model/property mappings
To mix-in methods onto model classes, a connector must choose what functions to offer. Different types of connectors implement different interfaces that group a set of common methods, for example:
- Database connectors
- create, retrieve, update, and delete methods, such as create, find, findById, deleteAll, updateAll, count
- E-mail connector
- send()
- Storage connector
- Container/File operations, such as createContainer, getContainers, getFiles, upload, download, deleteFile, deleteContainer
- Push Notification connector
- notify()
- REST connector
- Map operations from existing REST APIs
- SOAP connector
- Map WSDL operations
This article focuses on building a connector for databases that provide full create, retrieve, update, and delete capabilities.
Understand a database connector with create, retrieve, update, and delete operations
 </figure>
</figure>
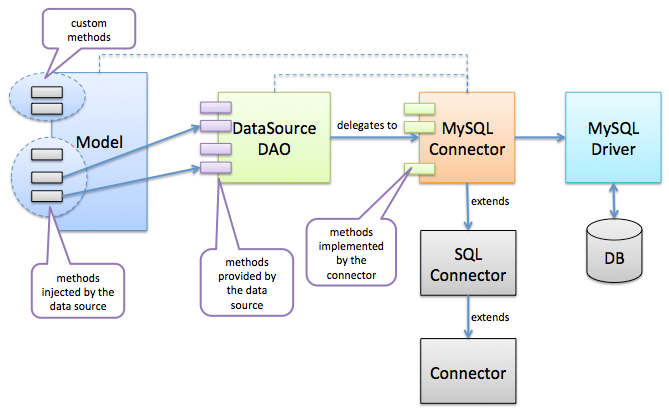
LoopBack unifies database connectors so that a model can choose to attach to any of the supported database. There are a few classes involved here:
-
PersistedModelClass defines all the methods mixed into a model for persistence.
-
The DAO facade maps the PersistedModel methods to connector implementations.
-
Create, retrieve, update, and delete methods need to be implemented by connectors.
The following sections use the MySQL connector as an example to walk through how to implement a connector for a relational database.
Define a module and export the initialize function
A LoopBack connector is packaged as a Node.js module that can be installed using npm install.
The LoopBack runtime loads the module via require on behalf of data source configuration, for example, require('loopback-connector-mysql');.
The connector module should export an initialize function as follows:
// Require the DB driver
var mysql = require('mysql');
// Require the base SqlConnector class
var SqlConnector = require('loopback-connector').SqlConnector;
// Require the debug module with a pattern of loopback:connector:connectorName
var debug = require('debug')('loopback:connector:mysql');
/**
* Initialize the connector against the given data source
*
* @param {DataSource} dataSource The loopback-datasource-juggler dataSource
* @param {Function} [callback] The callback function
*/
exports.initialize = function initializeDataSource(dataSource, callback) {
//...
};
After initialization, the dataSource object will have the following properties added:
connector: The connector instancedriver: The module for the underlying database driver (mysqlfor MySQL)
The initialize function calls the callback function once the connector has been initialized.
Create a subclass of SqlConnector
Connectors for relational databases have a lot of things in common.
They are responsible for mapping create, retrieve, update, and delete operations to SQL statements.
LoopBack provides a base class called SqlConnector that encapsulates the common logic for inheritance.
The following code snippet is used to create a subclass of SqlConnector. The settings parameter is an object containing the data source settings.
function MySQL(settings) {
// Call the super constructor with name and settings
SqlConnector.call(this, 'mysql', settings);
//...
}
// Set up the prototype inheritence
require('util').inherits(MySQL, SqlConnector);
Implement lifecyle methods
A connector must implement connect(), disconnect(), and optionally ping() methods to communicate with the underlying database.
Connect to the database
The connect method establishes a connection to the database.
In most cases, it creates a connection pool based on the data source settings, including host, port, database, and other configuration properties.
MySQL.prototype.connect = function (cb) {
// ...
};
Disconnect from the database
The disconnect method closes a connection to the database. Most database drivers provide an API to disconnect.
MySQL.prototype.disconnect = function (cb) {
// ...
};
Ping the database
Optionally, implement a ping method to test if the connection to the database is healthy.
Most connectors implement it by executing a simple SQL statement.
MySQL.prototype.ping = function(cb) {
// ...
};
Notes for creating non-database connectors
The above documentation focuses on database connectors. Here are some notes on creating other kinds of connectors contributed by Gaurav Ramanan.
Warning:
This section is still a work in progress and is incomplete.
Creating the Connector
Connectors must inherit from require(loopback-connector).Connector
Connector modules must export an initialize() function.
The initialize function gets data from the dataSource as parameters. A new instance of the connector is to be setup in dataSource.connector.
For example, from loopback-connector-mongodb:
exports.initialize = function initializeDataSource(dataSource, callback) {
if (!mongodb) {
return;
}
var s = dataSource.settings;
s.safe = (s.safe !== false);
s.w = s.w || 1;
s.url = s.url || generateMongoDBURL(s);
dataSource.connector = new MongoDB(s, dataSource);
dataSource.ObjectID = mongodb.ObjectID;
if (callback) {
dataSource.connector.connect(callback);
}
};
Override methods defined in Connector
- Which methods methods must be overriden?
- What does calling the base class from within our Connector (
super()) do?
CRUD Methods are to be derived from the DAO Facade
-
Should connectors inherit from https://github.com/strongloop/loopback-datasource-juggler/blob/master/lib/dao.js ?
No,
DataAccessObjectis mixed into model class when a model is attached to a data-source. By default,juggler/lib/dao.jsis used. However, connectors may provide their ownDataAccessObject- this would be the case for connectors that do not implement/support LoopBack’sPersistedModelAPI. Seehttps://github.com/strongloop/loopback-datasource-juggler/blob/9a76fb4c071cc4c811d0553980caae66bc8d2644/lib/datasource.js#L117 -
Again, which methods should be required to implement?
If the connector is compatible with the built-in
DataAccessObject, then it needs to implement methods called fromDataAccessObjectmethods. You can find the required connector methods by runninggrep "connector\.[a-zA-Z]*(" lib/dao.js. Here is the distilled list:- connector.create
- connector.updateOrCreate (optional, but see below)
- connector.replaceOrCreate (a new feature - work in progress)
- connector.findOrCreate (optional, but see below)
- connector.buildNearFilter
- connector.all
- connector.destroyAll
- connector.count
- connector.save
- connector.update
- connector.destroy
- connector.replaceById (a new feature - work in progress)
- connector.updateAttributes
-
If we implement a
create()and anupdate()and don’t specify anupdateOrCreate()willdao.jshandle this for us automatically, through https://github.com/strongloop/loopback-datasource-juggler/blob/master/lib/dao.js#L437 ?Yes, loopback-datasource-juggler will handle
updateOrCreateandfindOrCreateif they are not provided by the connector. However, I am strongly recommending to implement these methods, because only the connector can provide a version that guarantees atomicity. The juggler shim makes two database/datasource calls (find and then update/create depending on the result), which creates a race condition. I.e. if you callupdateOrCreate({ id: 123, name: 'foo' })twice at the same time (in parallel), the second call is very likely to fail as the second “find” will return before the first “create” was called, and thus the second call will attempt to create a record that already exists.
Some methods have to implemented for relations to work.
https://github.com/strongloop/loopback-datasource-juggler/blob/master/lib/relation-definition.js
For example, findOrCreate() is required for the add() function of hasAndBelongsToMany relations.
https://github.com/strongloop/loopback-datasource-juggler/blob/master/lib/relation-definition.js#L1028
Which method is required for Relations to work?
It should be enough to use the defaultDataAccessObject and then implement the connector methods as described. See the source code of the
memory connector.
It does support relations and doesn’t implement any special methods for that.